Monitoring Grid Frequency Data via Tesla Wall Charger Endpoint
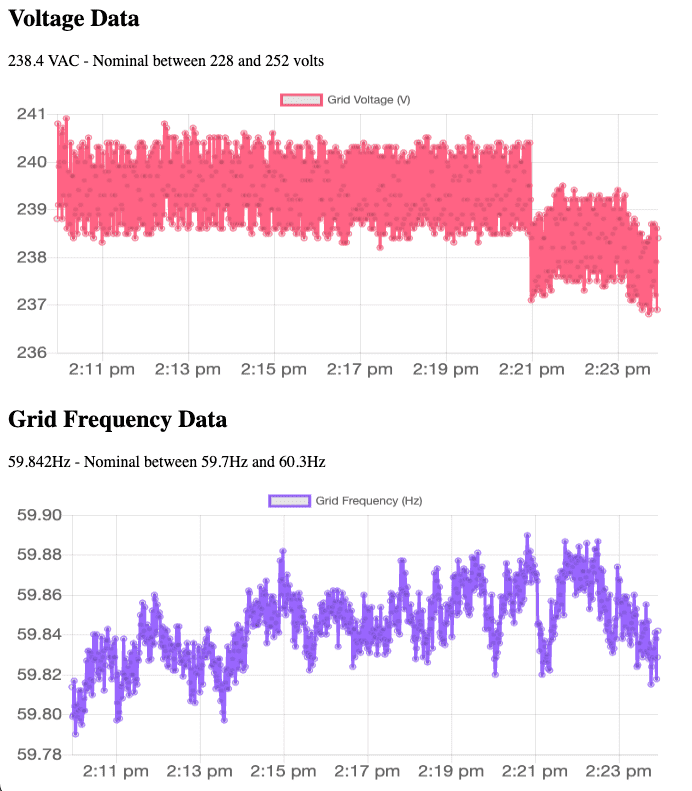
Monitoring and collecting data from Tesla’s Wall Charger is a great way to track and analyze the stability and reliability of your local power grid. If you have a Tesla Wall Connector (Gen 3), you can track this data for free! The data can be valuable for individuals looking to install electric vehicle (EV) charging … Read more